
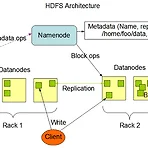
 Hadoop HDFS 사용자 생성 파일 테스트
Hadoop HDFS 사용자 생성 파일 테스트
오랜만에 다시 Hadoop을 테스트하기 위해 Shell 창을 열어 Hadoop명령어를 치려니 왠지 뭔가 생소하게 느껴지는 것이 새롭다. 오늘은 그 동안 삽질하면서 설치한 Hadoop에 책에서 나오는 코딩 된 HDFS 소스 파일들을 컴파일하고 실행하는 방법을 남겨보고자 한다. 그리고, 이번 테스트를 하면서 앞에서 실수한 부분을 다시 수정하고자 한다. 앞에서 하둡을 설치할 때 나는 자바 버전을 1.7 버전으로 설치를 하였었다. 그런데, 자바파일 컴파일을 하는 과정에서 컴파일이 되지 않고 컴파일은 되었다 할지라도 실행과정에서 java version 이 맞지 않는다는 오류를 발견할 수 있었다. 그래서, 하둡 홈폴더에 있는 build.xml 파일을 확인해서 보니, 자바버전이 1.6 버전으로 되어 있다는 것을 알았..
 Hadoop 명령어 정리
Hadoop 명령어 정리
나는 이런 Hadoop 명령어 정리를 해 놓은 블로그나 웹사이트를 검색할 수 없었기 때문에 블로그로 정리해 공유하고자 한다. 실은 이것보다도 더 큰 이유는 몇일동안 Hadoop을 공부하면서 왜 서버를 내렸다 올리면 HDFS가 실행이 안 될까? 하는 의문을 가졌기 때문이다. 구글링을 해보고 책을 봐도 특별한 해답이 보이질 않았는데, 오늘 드디어 그 비밀을 알아냈다. 하둡 설치 폴더에서 hadoop을 보면 hadoop은 스크립트 파일이다. 특정 언어로 프로그래밍한 것이 아니라, 단순한 Linux Shell Script 라는 것이다. hadoop 명령을 그냥 치면 다음과 같이 hadoop 명령어들이 나오는데, 해답은 저 명령어 안에 있었다. 그래서 오늘은 hadoop 명령어들을 한번 정리해 보도록 하겠다. U..
 VM Ubuntu에 Hadoop(Stand-Alone) 설치하기
VM Ubuntu에 Hadoop(Stand-Alone) 설치하기
작년 10월 무렵에 하둡을 한번 설치를 해 본적이 있었다. 그때는 메뉴얼도 잘 안나와 있고, 무슨 소리인지 잘 몰라서 고개만 갸우뚱거리다가 그냥 넘어갔는데, 요번에 하둡을 다시 설치해 볼일이 생겨 구글링을 해 보니 작년하고 다르게 쉬운 메뉴얼들이 많이 나와 있었다. 그래서, 가장 간단하면서도 빠르고 쉽게 하둡을 설치할 수 있는 방법을 글로 적어보도록 하겠다. 대부분의 리눅스에는 OpenJDK가 설치되어 있다. 하둡은 자바이기 때문에, 자바를 함께 설치를 해야하는데 sun jdk가 가장 궁합이 잘 맞는다고 한다. 그래서, 이번에는 Ubuntu에 자바 설치하는 것부터 삽질해 보았다. 1. Sun jdk1.7을 설치한다. Oracle jdk7을 설치해야하는줄 알았는데, 나중에 프로그래밍을 하는데 Java Ve..
- Total
- Today
- Yesterday
- Redhat
- neutron
- 김미경
- 네트워크
- 뉴트론
- Python
- sdn
- 오픈스택
- 클라우드
- 레드햇
- 후기
- 하둡
- OVN
- command
- 세미나
- Swift
- ubuntu
- cpu
- 설치
- 파이썬
- Java
- 오픈쉬프트
- NOVA
- 명령어
- Network
- install
- openstack
- 우분투
- 쿠버네티스
- 컨테이너
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |